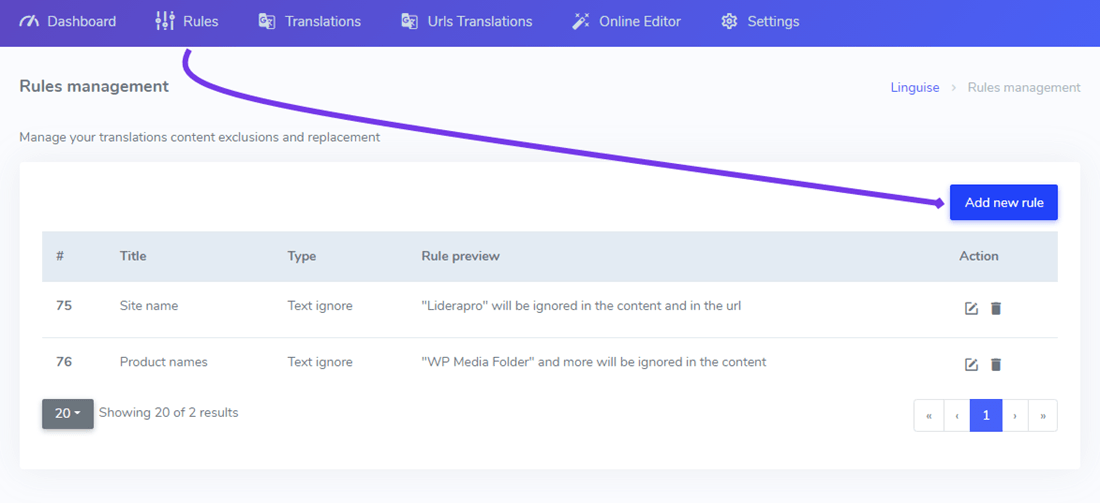
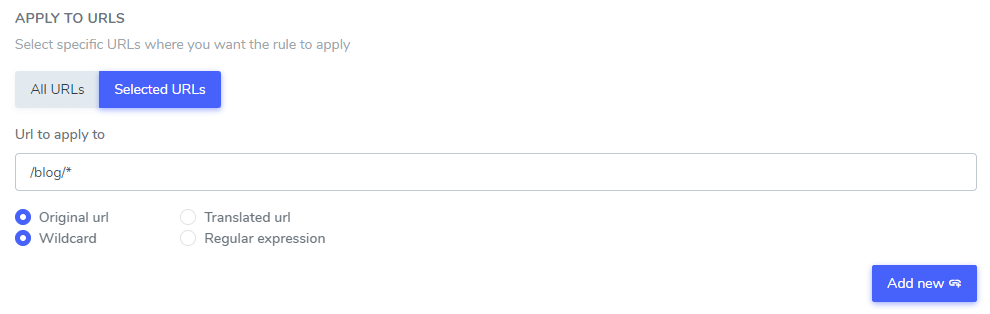文本忽略规则将避免在您可以定义的某些条件下翻译某些文本。
然后,您将能够更新文本忽略规则详细信息,主要是:
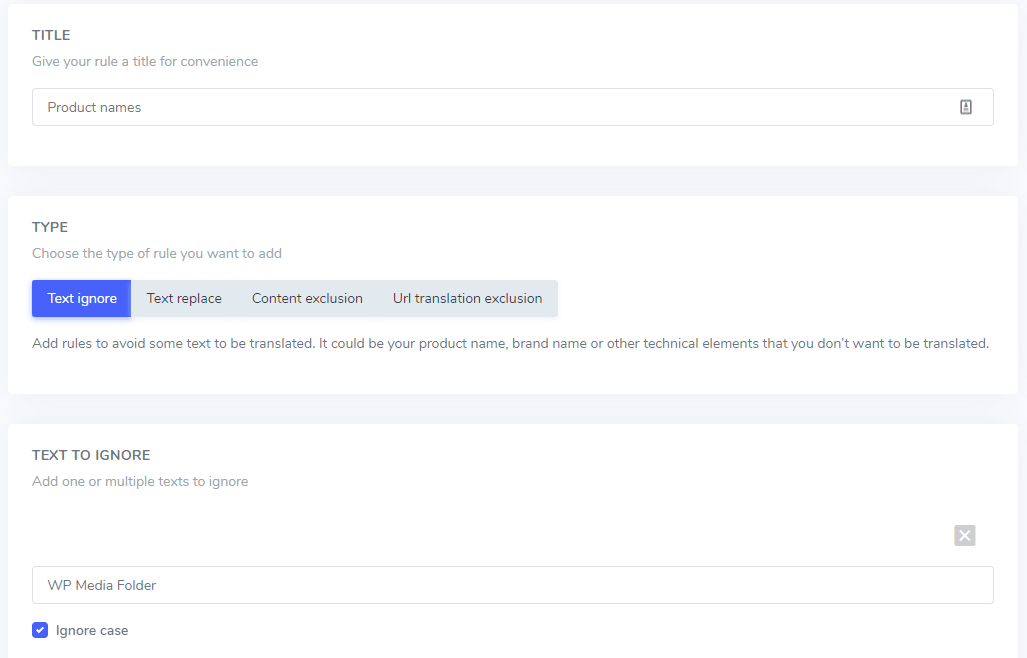
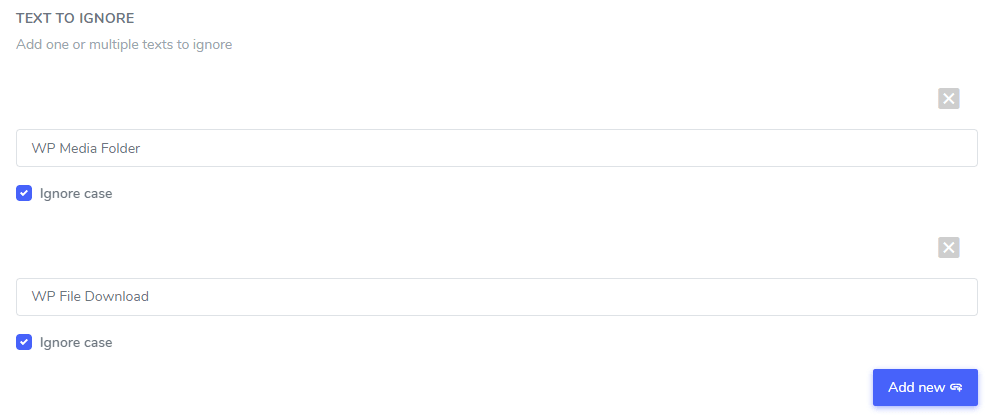
在要忽略的文本字段中,您可以添加几个要在同一规则下排除的文本表达式,在我们的示例之后,带有多个商标名称排除的屏幕将如下所示:
忽略大小写设置:文本输入区分大小写,这意味着如果选中该复选框,则规则会将大小写字母解释为相同。 翻译排除示例:“ Prime V ideo Player”和未激活区分大小写的“prime v ideo player ”都将被排除。
设置要在翻译中忽略的文本后,您可以排除所有网站 URL 上的文本(使用“所有 URL”选项)或某些特定页面 URL 上的文本。
在此示例中: “Netflix 播放器”、“PrimeVideo 播放器”、“YouTube 播放器”将从 www.domain.com/blog/ 开头的所有网站 URL 的翻译中排除
可以混合多个 URL 条件来覆盖例如多个翻译语言的 URL。
使用正则 表达式( RegEx ) 确实需要对 所涉及的语法 和概念。 正则表达式对于 URL 和单词有不同的语法。
虽然通配符更容易掌握和用于简单的任务,但 RegEx 提供了更高级和灵活的模式匹配功能。
以下是正则表达式的单词匹配模式的一些常见示例:
您还可以在此处阅读有关正则表达式的更多详细信息: https
如果您对此感到困惑,我们建议在常规使用中通配符 如果您有任何疑问,您可以随时填写联系我们表格与我们联系!
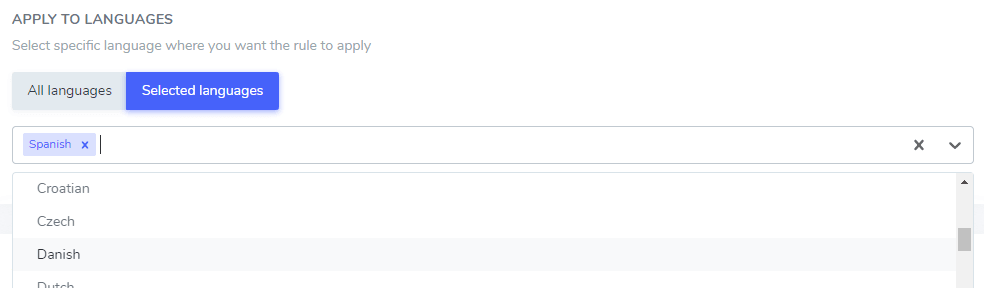
您添加的文本忽略只能在某些特定语言或所有语言中排除。 这非常方便,因为某些单词在不同语言中可能具有相同的拼写,但只需要在一种语言中排除。 例如,“ilimitados”这个词在葡萄牙语和西班牙语中是相同的。
在此示例中: “Netflix 播放器”、“PrimeVideo 播放器”、“YouTube 播放器”将仅从西班牙语翻译中排除。
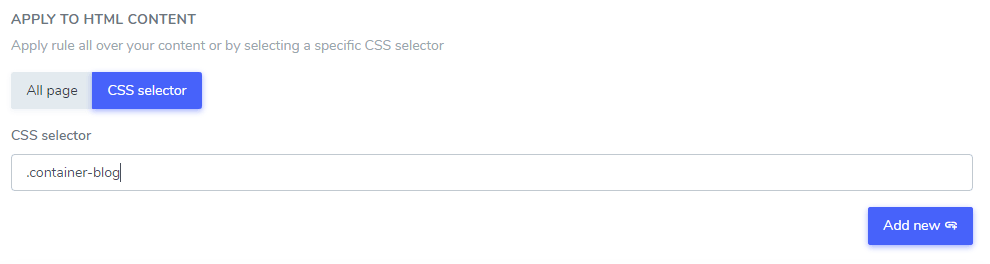
可以使用一个或多个 CSS 选择器将您添加的文本忽略从 HTML 内容的一部分中排除。 使用浏览器代码检查器,您可以获得任何 CSS 选择器并将其添加为以下内容。
获取 CSS 选择器:
并将其添加到规则设置中:
在此示例中: “Netflix 播放器”、“PrimeVideo 播放器”、“YouTube 播放器”将仅在 .blog CSS 选择器中的 HTML 内容中从翻译中排除
您添加的忽略文本可以从 URL 本身中排除,这意味着“PrimeVideo 播放器”将保持在 URL 中的原样。 例如:“www.domain.com/prime-video-player”将不会被翻译。
URL 修改:注意修改实时网站内容上的 URL 的配置。 它可能会产生您需要重定向的 404 个 URL
您可以在 HTML 内容的任何位置包含一个标签以从翻译中排除: translate=”no”
在HTML容器下找到的所有内容将不被翻译,包括所有子元素。
按标记排除HTML的示例:
<div translate=”no”>
<p>这段文字根本不会被翻译</p>
</div>