

Table of Contents
Add text to ignore
The text ignore rule will avoid some text to be translated on certain conditions you can define.
This is usually the first type of rule you’ll add to your website translation to exclude, for example, your product or company name. To add such rule, connect to your Linguise dashboard > click on Rules > Add new rule.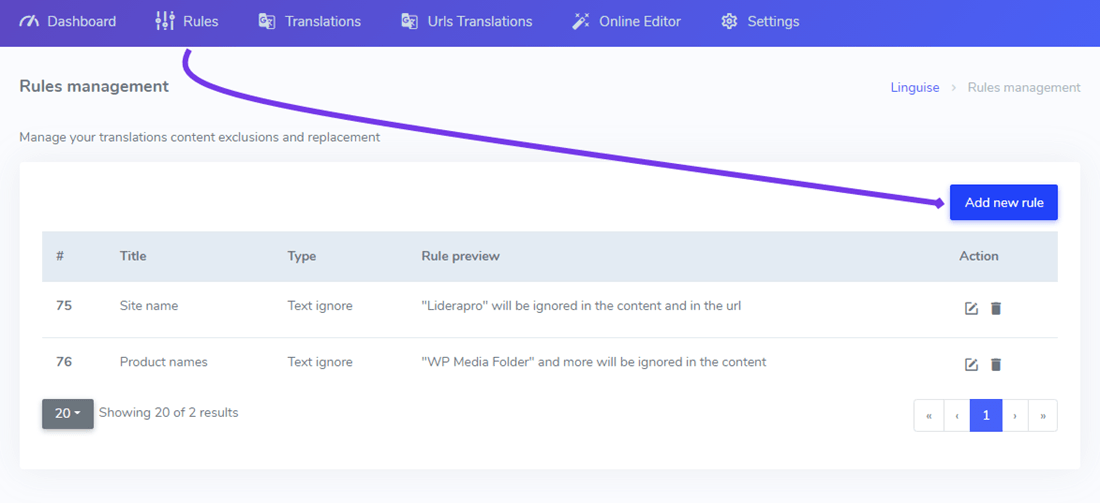
You will then be able to update the text ignore rule detail, mainly:
- The text you want to exclude
- The conditions of the text exclusion
- The rule title (visible only by you in Linguise dashboard)
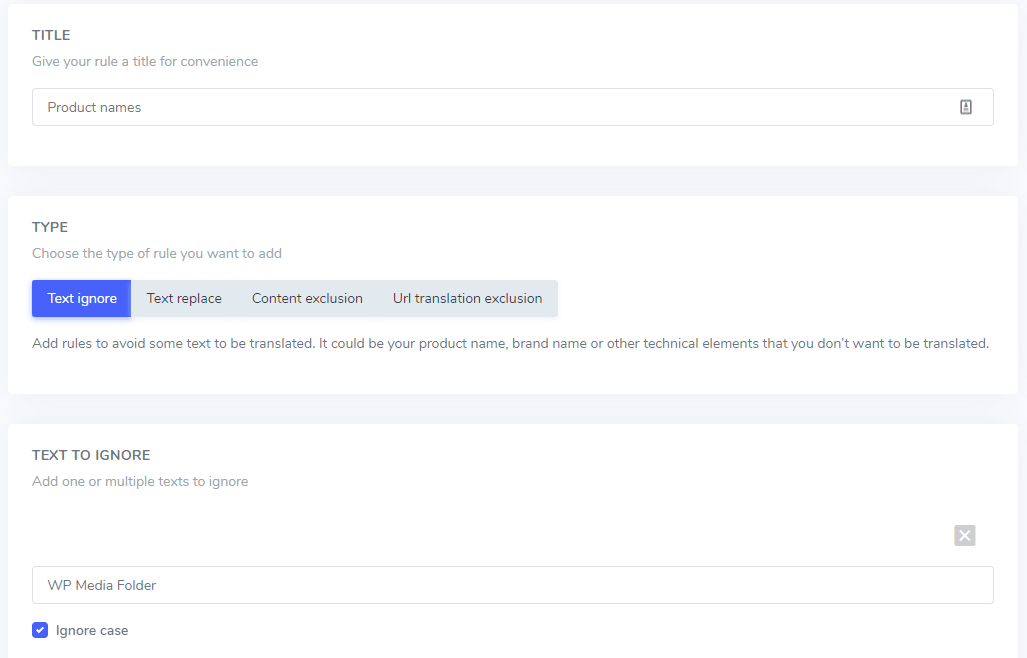
In the text to ignore field you can add several text expression to be excluded under the same rule, following our example, the screen with several brand names exclusion will looks like that:
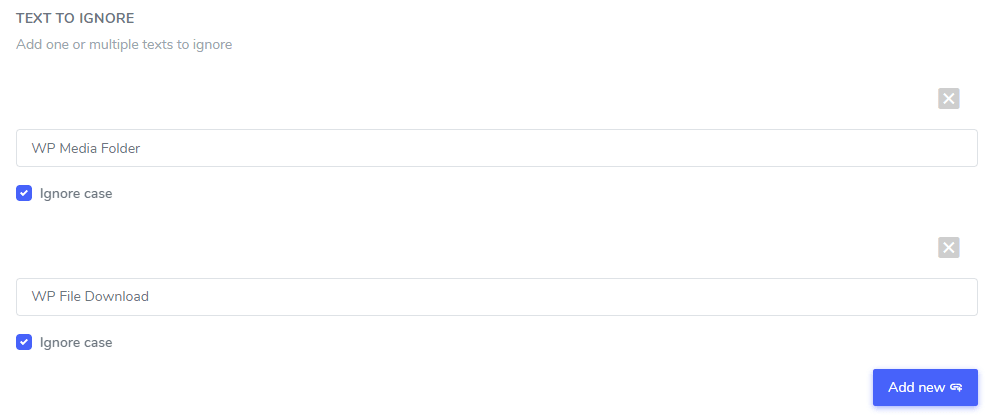
Ignore case setting: the text input is case-sensitive, meaning that if the checkbox is checked, the rule will interpret uppercase and lowercase letters as being the same. Example for a translation exclusion: “PrimeVideo player” and “primevideo player” with case-sensitive not activated will both be excluded.
Ignore text by URLs
Once you’ve setup the text to ignore from translation, you can exclude the text on all your website URLs (using ALL URL option) or on some specific pages URLs.
- Original URL / Translated URL: Ignore the text from translation on a specific URL from the original language or from a specific URL from a translated language
- Wildcard / Regular expression: Ignore the text from translation on a specific URL using wild card or regular expression
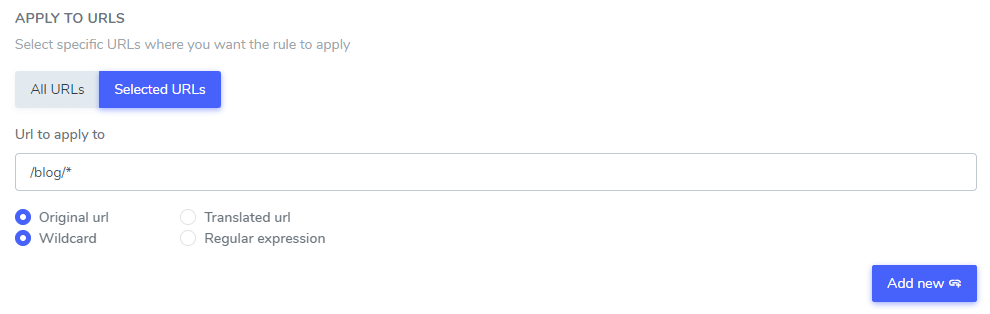
In this example: “Netflix player”, “PrimeVideo player”, “YouTube player” will be excluded from the translation in ALL the website URLs that starts by www.domain.com/blog/
Several URLs conditions can be mixed to cover, for example, several translated languages URLs.
Regular Expressions pattern matching
Using regular expressions (RegEx) does require some understanding of the syntax and concepts involved. Regular Expressions has different syntax for URL and word.
While wildcards are easier to grasp and use for simple tasks, RegEx provides more advanced and flexible pattern matching capabilities.
Here’s some Common example for Word Matching Pattern of Regular Expression:
- Match any word starting with “Light”:
RegEx: Light\w
Explanation: Matches any word that starts with “Light” followed by zero or more word characters (\w). This could match “Light”, “Lightbulb”, “Lightweight”, etc. - Match any word ending with “Light”:
RegEx: \w*Light
Explanation: Matches any word that ends with “Light” preceded by zero or more word characters. This could match “Sunlight”, “Daylight”, “Spotlight”, etc. - Match “Linguise” as a whole word:
RegEx: \bLinguise\b
Explanation: This will match any string that consists of exactly the characters “Linguise” word. This will also ensure it doesn’t match with other words like LinguiseApp but only “Linguise”.
You can also read more details about Regular Expression here: https://www.regular-expressions.info/
If you’re confused about this, we recommend using Wildcard over Regular Expression for regular use.
If you have any concern, you can always get in touch with us by filling Contact Us Form!
Ignore text by language
The text ignore you’ve added can be excluded only in some specific language or in all languages. This is pretty handy as some words may have the same spelling in different languages but require an exclusion only in one. For example, the word “ilimitados” is the same in Portuguese and in Spanish.
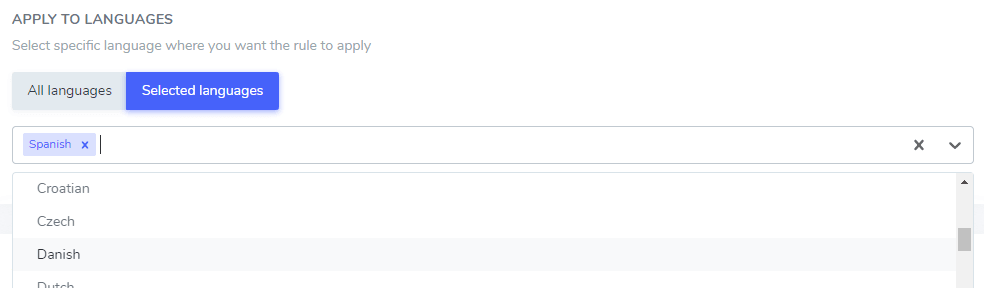
In this example: “Netflix player”, “PrimeVideo player”, “YouTube player” will be excluded from the translation only in Spanish.
Ignore text in HTML content
The text ignore you’ve added can be excluded from a part of your HTML content using one or several CSS selector. Using your browser code inspector, you get any CSS selector and add it as fallowing.
Get a CSS selector:

And add it in the rule setup:
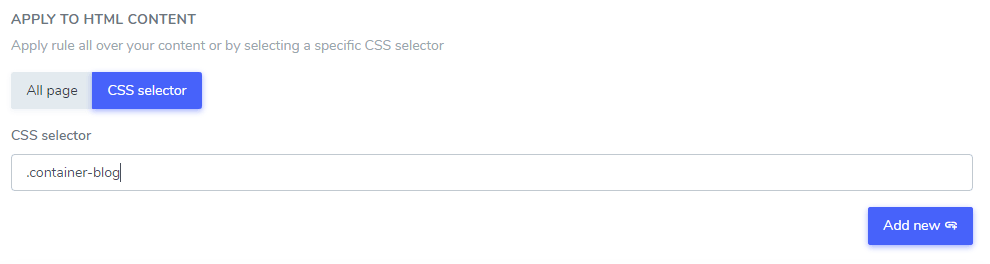
In this example: “Netflix player”, “PrimeVideo player”, “YouTube player” will be excluded from the translation only in the HTML content that is in the .blog CSS selector
Ignore text in URLs content
The text ignore you’ve added can be excluded from a URL itself, meaning that “PrimeVideo player” will stay as it is in URLs. For example: “www.domain.com/prime-video-player” won’t be translated.

URL modification: beware of a configuration that modifies URLs on live website content. It may produce 404 URLs you’ll need to redirect
Exclude content translation using a tag
You can include a tag anywhere in your HTML content to exclude from translation: translate=”no”
All the content found under the HTML container will NOT be translated, included all sub elements.
HTML exclusion by tag example:
<div translate=”no”>
<p>This text won’t be translated at all</p>
</div>